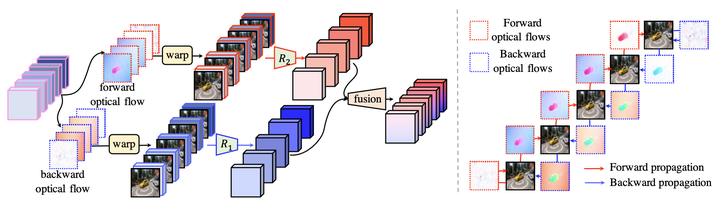
Abstract
Video super-resolution (VSR), with the aim to restore a high-resolution video from its corresponding low-resolution version, is a spatial-temporal sequence prediction problem. Recently, Transformer has been gaining popularity due to its parallel computing ability for sequence-to-sequence modeling. Thus, it seems to be straightforward to apply the vision Transformer to solve VSR. However, the typical block design of Transformer with a fully connected self-attention layer and a token-wise feed-forward layer does not fit well for VSR due to the following two reasons. First, the fully connected self-attention layer neglects to exploit the data locality because this layer relies on linear layers to compute attention maps. Second, the token-wise feed-forward layer lacks the feature alignment which is important for VSR since this layer independently processes each of the input token embeddings without any interaction among them. In this paper, we make the first attempt to adapt Transformer for VSR. Specifically, to tackle the first issue, we present a spatial-temporal convolutional self-attention layer with a theoretical understanding to exploit the locality information. For the second issue, we design a bidirectional optical flow-based feed-forward layer to discover the correlations across different video frames and also align features. Extensive experiments on several benchmark datasets demonstrate the effectiveness of our proposed method.